

Business Focused Abstract
Central Idea: Cobry and GCP services allow you to have better visibility over your business, making your decision-making process more manageable. In this write-up, I help our sales and marketing departments better understand the data from our Google Reseller Console, which has limited reporting functionality.
Dev Focused Abstract
Central Idea: Creating an ETL pipeline from an external API source to Looker is easy when using GCP.
Why did we decide to do this?
If you are anything like us here at Cobry, you live and breathe data. We believe that having accurate and readily available data is a massive advantage to any company. This is how our data lake (or data loch, as we like to say) initiative began a couple of months ago.
And in case you’re wondering what a data loch is, imagine a ‘space’ (could be a Shared Drive, a dataset in BigQuery, or even a folder on a hard drive if you’re feeling retro) where you store all sorts of data that your company generates. The sources are all your third-party tools, internal processes and customer projects; you name it, it all goes in the loch.
But every data lake must start with a stream. In the case of this blog, the stream we wanted to add to our data lake was our Google Reseller information. This dataset contains the types and number of licences that customers buy from us, which is handy information. We want to be able to analyse this data and use it to gain visual insights: maybe we need to bump sales for a particular licence type, or we just want to see which types generate the most revenue. We were curious, and we wanted answers!
This is how we got to this point. Keep reading… it’s going to get better!
The Technical Considerations
You’ve reached this point, so my introduction didn’t ultimately bore you. Worry not; this is where we start getting serious.
We had a goal in mind, and your trusty writer had to find a way to achieve it. And, of course, things are never as easy as they seem. We had to consider the following:
- The solution needed to be cost-efficient: we didn’t want to spend a lot to gain a little.
- There should only be one snapshot taken per day: our licences don’t fluctuate very much day-to-day. More snapshots mean a higher cost; we don’t want that.
- The solution needed to be fast to develop and deploy: we didn’t want to lose time on over-engineering it.
- We wanted the data to be easily accessible to anyone that might need to use it (more on this later)
And lastly:
- We wanted our solution to be easy to debug and adapt to our future needs: we live in times where things change very fast, and if your code can’t adapt in time, it will be left behind.
This was the state of things. Next, we will look at the tools we chose for the job that would meet all of the criteria described above. Read on.
Tools/Services Used
If you were to think about our system in terms of characters of a big score bank heist movie, our team was composed of the following:
- The Muscle - Cloud Functions - Our working horse, doing most of the heavy lifting, opening gates, carrying bags of cash (*ahem✊, data), and all that jazz.
- The Plan Master - Cloud Scheduler - If you weren’t sure about a particular plan detail, this was your person. They knew exactly when each step needed to start and the required resources.
- The Hideaway - Cloud Storage - This was our central hub and the stopping point for our big catch before storing it.
- The Backup Plan - Cloud Logging and Monitoring - When things go smoothly, you don’t need to worry about this. But if you’ve ever watched a heist movie, you know it’s not always like that. That’s why you need to have a way of figuring out when something goes wrong and, more importantly, gain insights into how you can remediate the problem.
- The sunset end scene at the beach, with everyone sitting on sunbeds and sipping drinks - BigQuery & Looker- This is it. We made it to our destination. But is this the end? Of course not. We’ve got even bigger fish to catch. And with all this money (*ahem✊ data), many more opportunities will open in front of us.
Of course, some other actors played minor but still essential roles (such as Secret Manager, used to store service account keys securely), but these were the main stars.
High-Level Solution and Steps
You could split the solution that we built into four steps:
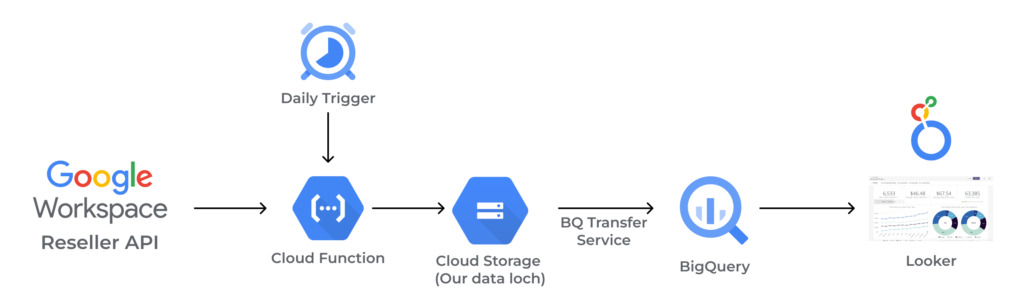
- Extraction
This stage was all about retrieving customer data from our Reseller console into a storage solution (Cloud Storage), where it becomes much easier to access and use. We used Cloud Scheduler to set up a daily trigger to extract the data using a Cloud Function, which we wrote using Python. For this step, we just wanted to get the raw data in its purest form.
- Transformation
The transformation stage encompassed our efforts to trim unnecessary data and get it into a format suitable for our data warehouse (BigQuery) and, ultimately, Looker. Again, we used a timed trigger (that activated about 30 minutes after the extraction stage had been completed) and a Cloud Function to achieve this. The script would take the raw data, generate a transformed file, and then save it to a bucket in Cloud Storage.
- Load
One of the most straightforward steps in this whole operation was the load step. This is where we moved the data from our data lake (Cloud Storage) to our data warehouse (BigQuery) using the Data Transfer service provided by BigQuery.
- Consumption
The very last step was to connect the data to Looker and give access to our analysts to start creating insights on the licences we sell. This was a breeze since Looker can directly communicate with database providers such as BigQuery and many others.
The Results and Business Outcomes
As we said previously, we wouldn’t want to do all of this if it wouldn’t be helpful to us. So, what did we get out of it?
First of all, we now have a way to visualise our licences and analyse how our revenue is split by licence type, what our most sold licences are, and other insightful metrics. This is all invaluable information we can use to make better decisions.
Secondly, we now have a way of automatically storing the historical data related to our licences and can always go back and check how many licences our customers had on a specific date. This is great for forecasting trends, something Looker can help you achieve automatically, so there is no need to buy extra software to accomplish this.
One last point to make is that as we add more data sources to our data warehouse, the benefits we get are not linear but rather exponential. The more data we can bring, the more connections we can make, which allows us to get a clearer picture of our business. It’s definitely something to consider!
The Cultural Considerations
People just want to get their work done fast. People don't want to go through monthly manual extraction steps, followed by hours spent in front of a Spreadsheet trying to generate charts and metrics. Multiply this by the number of applications generating data you have, and you get a recipe for disaster waiting to happen.
The solution to this problem is what the system we built promises. The data is always there for you, ready to be analysed, right at your fingertips; whether that's a data analyst wanting to dip into the data on BigQuery using Jupyter notebooks or SQL, or a business user just wanting to get a general perspective of the business.
Thus, if you are interested in creating/expanding your own data lake, drop us your email below. We'll get in touch and we’ll be able to help you with every step of your data process, from extraction to dashboarding, to delivering actual value.
